11. 복제
"장애는 항상 발생한다" 라는 사실로 DB 관리 시스템에 복제(replication)는 핵심적 요소
복제 기본 개념#
- 여러 MongoDB 서버(노드)에 데이터를 분산하고 관리하는 것
- 복제 세트(replica set) 매커니즘 제공
- 프라이머리 노드에 쓰기
- 세컨더리 노드에 읽기
- 비동기적으로 세컨더리 노드에 쓰기 반영
- 자동 장애조치(failover) 보장
- 프라이머리 노드 장애시 세컨더리 노드가 자동적으로 프라이머리 노드로 승격
- 복제 세트는 과반수의 멤버노드에 기록될 때까지 실제로 커밋된 것으로 간주되지 않는다
사용 예#
- 중복성
- 복제는 비동기적이라 프라이머리 성능에 영향이 없음
- 복제 지연이 있을 수 있음
- 장애복구
- 비상 시 중복노드로 전환 가능
- 리소스를 많이 사용하는 연산은 세컨더리 노드에서 실행
- 인덱스 구축시 세컨더리에 먼저 구축 후 프라이머리 전환 가능
- 복제 노드 간 로드 밸런스
한계#
- 할당된 하드웨어가 주어진 일을 처리할 수 없을 수 잇음
- 읽기, 쓰기 비율이 50% 넘을 때 (예, 복제 지연)
- 앱에서 일관성 있는 읽기가 필요할 때
복제 세트 관리와 장애조치#
셋업#
- 최소 구성은 세 개의 노드 권장 (과반수 확보를 위한)
- 유형: 데이터 보유 세 노드, 데이터 보유 2 노드 + arbiter를 보유한 1 노드
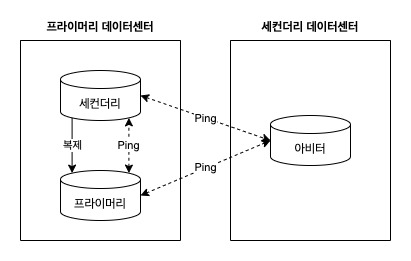
- 아비터 (arbiter)
- 프라이머리 선출엔 참여하지만, 그 어떤 데이터를 가지지 않는 경량 mongod 서버
복제 작동 방식#
oplog#
- oplog로 데이터 복제 기능 지원
- capped 컬렉션
- 모든 복제노드의 local DB내 있음
- DB에 대한 수정사항 기록
- oplog의 크기에 따라 복제 중지가 발생할 수 있음
- 연산 규모에 맞는 oplog 크기를 가져야 함
쓰기 시, oplog 수행 순서
- 프라이머리에 쓰기 수행
- 프라이머리에 oplog 기록
- 세컨더리 oplog의 최신 기록과 프라이머리에 oplog의 기록 비교
- 세컨더리 oplog 최신 기록 이후의 프라이머리 oplog의 질의를 세컨더리에서 수행
- 각 질의 수행마다, 세컨더리 oplog에 완료된 수행 질의를 oplog에 기록
heartbeat#
- 시스템 건강상태 모니터링으로 장애복구 지원
- 복제 세트의 각 노드들은 서로 핑을 주기적으로 날림
- 한 노드라도 반응이 없다면 장애복구 시작
- 노드들이 과반수가 넘지 않게 된다면 프라이머리가 세컨더리로 강등
- 계속 쓰기가 이루어지면 일관성이 깨져 앱이 비정상적으로 실행할 가능성이 높아짐
커밋, 롤백#
- 과반수에 쓰기연산이 반영되기 까진 커밋되지 않은 것으로 간주
- 여러 다큐먼트를 포함하는 쓰기작업은 원자적이지 않음
- 과반수 이상 복제되지 않을 경우, 롤백이 발생
- 노드 데이터경로의
rollback서브디렉터리에 조회 가능 - 쓰기 concern과 복제 지연 모니터링을 잘 이용하면 롤백문제를 경감하거나 피할 수 있음
장애 조치와 복구#
- 장애 모드
- 깨끗한 장애(clean failure)
- 데이터 파일이 손상되지 않음
- 네트워크가 재연결되거나, 프로세스가 다시 정상적으로 복구되면 해결
- 확실한 장애(categorical failure)
- 데이터 파일이 깨진상태
- 재동기화나 백업 파일로 조치
- 깨끗한 장애(clean failure)
드라이버와 복제#
앱에서 MongoDB와 연결, 연산 시 사용하면 유용한 옵션
쓰기 concern#
- 옵션 값
- w: 복제할 서버 수
- wtimeout: 지정된 시간내에 복제되지 못할 경우 에러
- 기본값은 무한적 블럭
- j: 쓰기전 저널링 강제 동기화 유무
읽기 확장으로 읽기 최적화#
- 읽기 선호도(read preference)를 통해 어떤 노드에서 읽을 건지 옵션으로 지정할 수 있음
- 제공되는 옵션: primary(Preferred), secondary(Preferred), nearest
태깅을 사용한 복잡한 복제 세트 관리#
- 각 노드별로 태그정보를 달아, 특정 태그정보 옵션을 이용해 지정된 노드에만 연산을 수행할 수 있음